DataDistillation
DATASET DISTILLATION
publication: 2018 arxiv
Facebook AI Research ###
github:https://github.com/ssnl/dataset-distillation ### 想法: ####
传统方法
传统对于数据集缩小的方法,都是挑选数据集中存在的数据作为子集。其是启发性的搜索,并且在数据集中无明显代表性的数据时理论上就是不合理的
#### 提出的方法
以优化神经网络参数的方式,来优化数据集。在代码实现中表现为,先用高斯分布生成指定数量的
算法逻辑:

实现细节:
 可以看到,其对于蒸馏的数据生成是采用了高斯分布进行初始化的随机数据。 ###
示意图:
可以看到,其对于蒸馏的数据生成是采用了高斯分布进行初始化的随机数据。 ###
示意图: 
- Random real images: We randomly sample the same number of real images per category.
- Optimized real images: We sample different sets of random real images as above, and choose the top 20% best performing sets.
- k-means: We apply k-means clustering to each category, and use the cluster centroids as training images.
- Average real images: We compute the average image for each category,
which is reused in different GD steps.
 ### 缺点 或 问题: 作者在文中提到DD对于参数的初始化很敏感,对于
### 缺点 或 问题: 作者在文中提到DD对于参数的初始化很敏感,对于进行的蒸馏数据集,可能只适用于 ,在文中的解决办法也只是应用了多个初始化。
DATASET CONDENSATION WITH GRADIENT MATCHING
publication: ICLR 2021
github:https://github.com/VICO-UoE/DatasetCondensation
想法:
传统方法:
启发式方法选择数据集的子集。 #### 提出方法: 与DD相同,获得一个人工数据集,使模型可以通过其来获得较高的泛化性。
但DD存在一些他提出的问题。他定义了两个数据集,原始的为T,人造的为S,他说直接用神经网络的参数
他的思想是对比两个数据集上的梯度,优化目标是使得两个数据集的梯度尽可能相似。也即提出了一种数据集的度量指标即数学特征:模型在数据集上的梯度。
算法逻辑:
 其中
其中 可以看出,他是从真实图像中随机取了ipc张,然后进行优化的
可以看出,他是从真实图像中随机取了ipc张,然后进行优化的
示意图:


缺点 或 问题:
论文在刚开始时提出了模型在S和T上的参数是不同的,又基于这两个数据集的参数可能很难对齐,然后提出了使用梯度进行比较数据集距离的方法,然后在后续的证明中又说在实验中发现D(S,T)close to zero,然后将其优化为一个参数???
像是先射箭再画靶;直接使用S,T进行优化理论上比较困难且存在一定问题->我们希望他们的距离尽可能小并且遵循相似的路径->于是我们采用了梯度,(并且我们发现他们的D就是小,于是我们用其中一个替代了参数).
没有在较大的数据集上进行测试
Dataset Condensation with Differentiable Siamese Augmentation
publication: ICLR 2021 ,与DC是相同作者
github:https://github.com/VICO-UoE/DatasetCondensation
想法:
现有的方法在合成数据集与完整数据集上的效果仍有很大差距;受启发于数据增强的效果,作者将数据增强融入到数据集构造中。
算法逻辑:
 与DC不同,在DSA中,参数与图像的更新均用SGD代替opt-algs,在实现中,DC和DSA的代码都用的sgd作为优化器。
### 实现细节: -
为了保证学习到图像增强后原本图像中存在的信息,选择对T和S进行相同的增强
### 示意图:
与DC不同,在DSA中,参数与图像的更新均用SGD代替opt-algs,在实现中,DC和DSA的代码都用的sgd作为优化器。
### 实现细节: -
为了保证学习到图像增强后原本图像中存在的信息,选择对T和S进行相同的增强
### 示意图: 

缺点 或 问题:
404
Dataset Condensation via Efficient Synthetic-Data Parameterization
publication: ICLR 2022
github:https://github.com/snu-mllab/Efficient-Dataset-Condensation
想法:
DC & DSA:
通过反向传播优化图像相当于对图像的每个像素进行优化,没有对合成图像引入规律性条件(个人理解为专家知识).也即没有更强的约束条件,存在解!=一定能找到解。就像全连接与卷积网络一样。 #### 本文方法: DC提出的梯度范数是有问题的,本文优化了优化并提出了新方法。
终极目标是
通过模型在S上的训练,提高在测试集上的表现,但这个目标太难实现,大家都采用中间目标来进行优化。DD是通过参数的改变,优化在T上的表现。而DC和DSA则是通过参数的梯度。
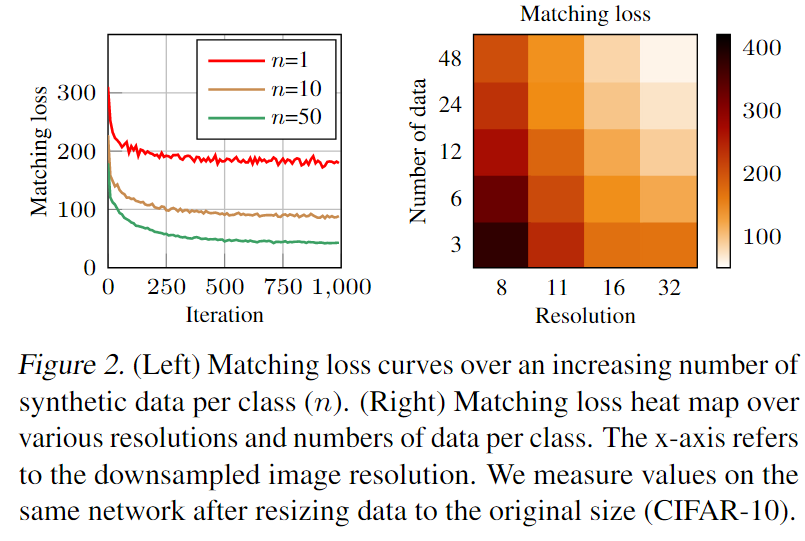 基于一种观测:随着S中每类图像数量的增加,match
loss降低,也即IPC越高,在S上的表现越好,于是作者提出了一种Multi-scaleformation的映射函数,不改变S的大小,而降S映射到另一个空间
基于一种观测:随着S中每类图像数量的增加,match
loss降低,也即IPC越高,在S上的表现越好,于是作者提出了一种Multi-scaleformation的映射函数,不改变S的大小,而降S映射到另一个空间 为什么相较于DSA,使用了T来更新参数
为什么相较于DSA,使用了T来更新参数 S与
S与 DSA有特征图,说采用原始图像会保留物体的姿态和颜色,但IDC可能不想被原始图像干扰?
### 示意图:
DSA有特征图,说采用原始图像会保留物体的姿态和颜色,但IDC可能不想被原始图像干扰?
### 示意图: 
缺点 或 问题:
为什么不直接提高S或者在S中引入函数,也即从根本上使用f对S进行改变,而是通过f将S映射到新空间。是因为优化可能引入递归?
Efficient Dataset Distillation via Minimax Diffusion
publication: CVPR 2024
github:https://github.com/vimar-gu/MinimaxDiffusion
想法:
传统样本迭代方法:
DC,DSA,IDC其优化空间与分辨率,图像数量呈正相关,为了更好的效果,必不可少的有更大的计算资源。
 #### 本文方法: 使用生成扩散技术,以及观察结果,基于数据集的
representativeness 和diversity生成样本S。
#### 本文方法: 使用生成扩散技术,以及观察结果,基于数据集的
representativeness 和diversity生成样本S。
也即使用diffusion,并且通过人工经验定义了两个优化目标,来得到一个数据集S。表现好并且相较于传统样本迭代方法,生成数据近似O(1).
算法逻辑:
 代表性方面:拉近最不相似的样本 多样性方面:推远离预测最相似的样本
代表性方面:拉近最不相似的样本 多样性方面:推远离预测最相似的样本 
实现细节:
示意图:


缺点 或 不足:
作者说本文方法主要针对于分类任务,可以考虑别的作用。
其中两个指标是作者提出来的,相当于人工经验限制解空间,可以从这方面考虑。 且其生成数据的方式相当于使用一个学习数据分布的模型去端到端的学习,可以从这方面改进。